

As manual document processing can no longer keep up, many teams are looking for Extend alternatives that offer better automation features and pricing. There’s a great deal of available options for automating data extraction, but finding the right one can be overwhelming. An ideal solution should work accurately with your specific documents, deliver output that match with your existing workflows, and remain cost-effective as you scale.
Read on this guide to learn more about the best Extend alternatives to streamline document workflows. For each solution, we will also highlight what makes it great and where it may have limitations.
Why Look For Extend Alternatives
Extend is known to be a powerful document processing stack designed for production use. It combines robust technologies to automate parsing, extraction, and classification within a single system.
However, not every team requires the level of infrastructure that Extend offers. Some organizations prefer simpler tools with easier setup, human-in-the-loop option, and minimal configuration. Others may look for solutions with no-code builders, lightweight APIs, or industry-specific features that fit their workflow.
Best Alternatives for Streamlining Document Processing
1. Fintelite
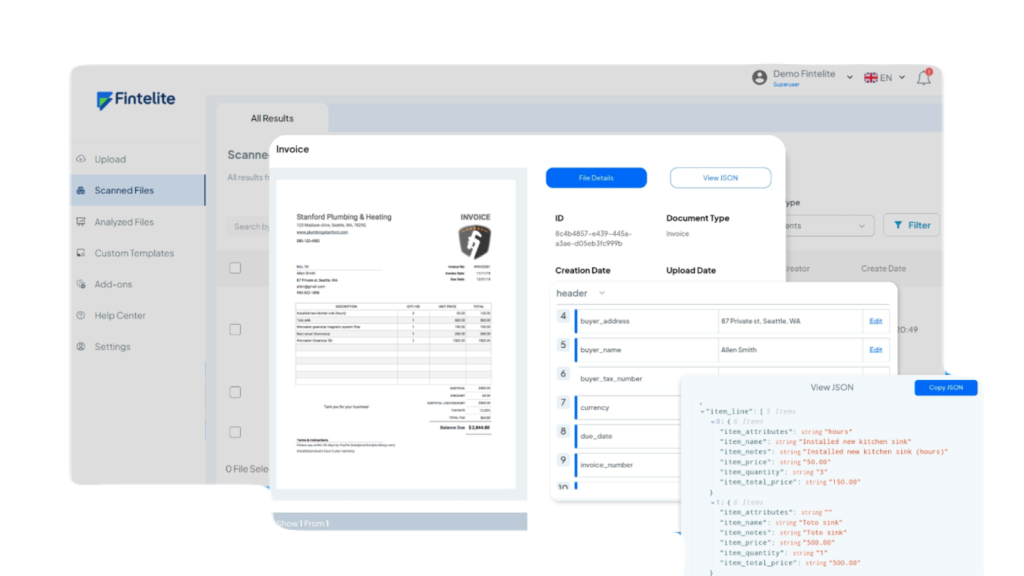
Fintelite stands as an intelligent document processing with AI-powered data parsing and extraction. It solves the time-consuming manual data entry by automatically retrieving structured document data, converting it into a specific format you can seamlessly push to your system. The platform leverages industry-best OCR technology that understands even the most complex tables and layouts, making it highly effective for processing multi-format documents like invoices, bank statements, receipts, financial statements, forms, and so on.
Pros:
- Allows custom parsing rules with simple, no-code creation
- Works template-free for different document layouts and designs
- Multiple export options to various formats (XLS, JSON, CSV, and more)
- API integration for end-to-end workflow across platforms
- Multi-language support for global document types
Cons:
- Relies on internet connectivity for access and processing
- Pricing may vary based on usage volume
2. Xtracta
Xtracta is a document intelligence platform that provides the automation needed to extract key information from documents. With AI that continuously learns, it capably handles a wide range of document types across various use cases. For full automation, it offers API access that enables automated data flows into your existing systems and business applications.
Pros:
- Smoothly handles document variations
- AI-powered accuracy across various document types
- Intelligent data extraction without dependency on templates
Cons:
- Limited language support for non-Latin alphabets
- API-based service that requires integration for full functionality
3. Docupipe
Docupipe is an AI-powered document processing solution that transforms unstructured document information into clean, structured data for business use. It uses advanced OCR and schema-based extraction to handle diverse documents, making it suitable for various operational needs. The implementation is especially useful to reduce manual steps in data entry, so teams can spend less time on collecting data and more time focusing on strategy and decisioning.
Pros:
- Custom schema-based extraction
- Supports many languages
- Automation-ready APIs and integrations
Cons:
- Some user reviews report the interface could be improved
- Learning curve for advanced use cases
4. Textract
As part of Amazon Web Services, AWS Textract is a powerful OCR solution that goes beyond simple text extraction. It automatically captures printed text and handwriting from documents, making them fully structured and usable for various purposes. With intelligent data recognition, businesses can efficiently process large volumes of documents without scalability problems, transforming paper-heavy operations into digitally streamlined workflows.
Pros:
- Smart data extraction from all document types
- Highly scalable as part of the AWS cloud ecosystem
- Integrates easily with other AWS services and APIs
Cons:
- Requires AWS ecosystem knowledge for setup and integration
- Some format and processing limitations depending on operation type
5. Tesseract
Tesseract is one of the most widely used open-source optical character recognition (OCR) for extracting text from scanned documents and images. It supports more than 100 languages and provides highly accurate data capture for multiple document types. Its flexibility and open-source nature allow developers to integrate it into custom workflows, automate document digitization, and scale processing pipelines without licensing costs.
Pros:
- Open-source and free to use
- Works offline and can be self-hosted
Cons
- Limited built-in support for advanced data extraction
- Setup and optimization may require technical expertise
Why Choose Fintelite for Faster and Simpler Data Extraction
From the explanations above, we can see that each solution comes with its own set of cutting-edge features designed to automate document processing and data extraction.
If you’re looking to automate data extraction in a more efficient and straightforward way, Fintelite is a strong option to consider. Fintelite is designed to be easy to use, helping teams reduce manual work without dealing with overly complex configurations. The platform focuses on delivering a smooth experience from the start by offering ready-to-use models that can extract structured data from various industry-specific documents such as invoices, purchase orders, receipts, and financial statements.
Does this spark your interest? Jadwalkan Demo to see how Fintelite works in practice and how it can solve document processing challenges in your business.
